Now, I’m getting interested in Redis. The concept of Redis seems to be different from other general purpose database like relational, document, graph databases; each of these employs a one-size-fits-all data model. By no free lunch theorem, these databases cannot store and fetch some kind of data efficiently. Some of this data can be efficiently handled by Redis since it provides specialized and primitive data structures. This specialty attracts me.
So, I intend to dig into Redis source codes. First step of code reading is to overview source codes and decide where to read. In this post, I visualize source code dependency graph.
Graphviz dot utility
A simple way to visualize a dependency graph is to use dot utility program in Graphviz. It can generate a graphical image from a plain text, e.g.,
# graph.dot
digraph "graph" {
a -> b
a -> c
c -> d
c -> e
}
This source represents a directed graph with 5 nodes a, b, …, e and 4 edges. Input this to dot:
dot -T png -o graph.png > graph.dot
Resulting output becomes:
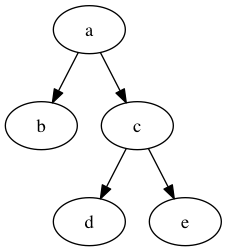
Extract source code dependencies
As above, we need to enumerate dependencies to visualize the graph but what source code dependency mean in fact? Here, I define a dependency is represented by #include statements (Redis is written in C).
Thus, dependencies are easily enumerated by a simple script like
cd $PATH_TO_REDIS_REPO
echo 'digraph "redis" {'
for i in *.h; do
for j in *.{h,c}; do
[[ ${i%.h} = ${j%.*} ]] && continue
grep -q -E "#include\s*[<\"]${i}[\">]" $j && echo "\"${j%.*}\" -> \"${i%.*}\""
done
done
echo '}'
(Nested loop is to exclude header files not in Redis repository such as stdin.h)
Here is the resulting dependency graph:
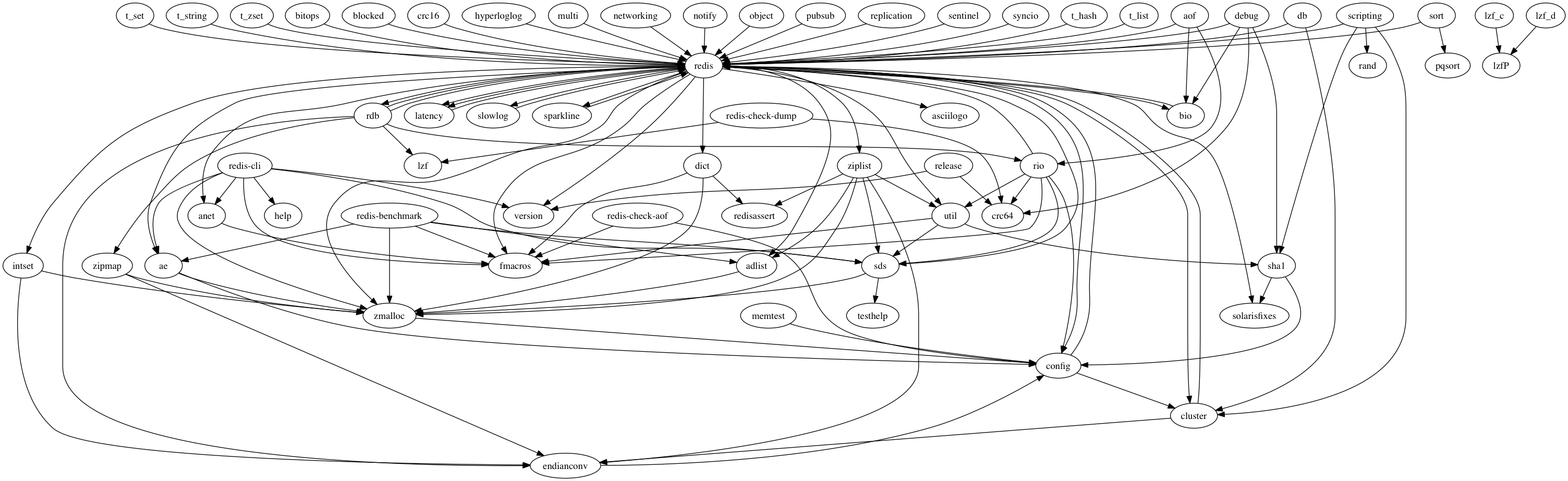
A bit complex. As you can see, almost source codes have dependency with redis.h. So I remove this trivial dependency and regenerated a graph:
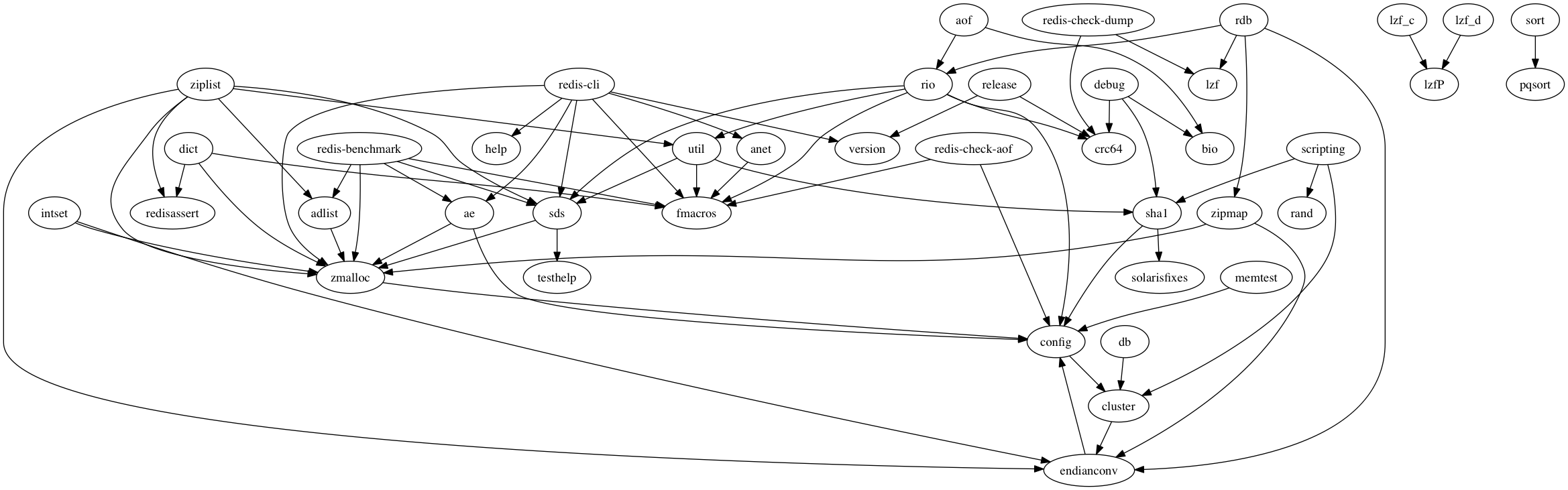
Looks little bit clear! Maybe I should understand zmalloc first.
comments powered by Disqus