In the previous post, a brief description about running Lua script on Redis and a code snippet to add a graph edge to a hash are given. In this post, an implementation of the Dijkstra’s shortest path algorithm is explained. I will not explain the algorithm itself since there are already so many articles explaining about it, e.g., Wikipedia’s page.
Priority Queue
A priority queue plays a primary role on the Dijkstra’s algorithm. The queue should hold a list of unvisited nodes ordered by a minimum cost to arrive a node. Thanks to Redis, sorted-sets can be used for this; a member and its score correspond to an unvisited node and the minimum cost of it respectively. Shift and push operations to this priority queue could be implemented like this:
-- dijkstra.lua:1
local function zshift(key)
local res = redis.call('ZRANGE', key, 0, 0, 'WITHSCORES')
redis.call('ZREMRANGEBYRANK', key, 0, 0)
return res[1], res[2]
end
local function zaddlt(key, score, member)
local s = redis.call('ZSCORE', key, member)
if not s or s+0 > score then
redis.call('ZADD', key, score, member)
end
end
The shift function retrieves the node with lowest score, i.e., lowest cost, by ZRANGE, then removes the entry by ZREMRANGEBYRANK and finally returns the node and its cost. The push operation is bit tricky due to the nature of a sorted-set; no two nodes can exist in the queue at the same time. Hence, a node and its associated cost should be added only if the cost is less than the one already existed in the queue. This is implemented as zaddlt. The time complexity of zshift and zaddlt is O(log(N)).
Dijkstra’s algorithm
Here is my implementation of the algorithm with Lua script. Following code is the initialization step.
-- dijkstra.lua:18
local graph = KEYS[1]
local queue = KEYS[2]
local n = ARGV[1]
local from = ARGV[2]
local to = ARGV[3]
local visited = {}
for i = 1, n do visited[i] = false end
redis.call('DEL', queue)
redis.call('ZADD', queue, 0, from)
First, it assigns command line arguments to local variables mostly for clarification. My Lua script takes two keys for accessing graph edges and the priority queue, and three extra arguments: the number of nodes, source and destination nodes. A Lua’s table visited is instantiated to look up which node is already visited. In lines 27 and 28, it clears the queue and pushes the first node with cost zero. The main part of the algorithm is:
-- dijkstra.lua:29
local cur, total = zshift(queue)
while cur do
visited[cur+1] = true
if cur == to then return total end
for i = 0, n-1 do
if not visited[i+1] then
local cost = getcost(graph, n, cur, i)
if cost and cost+0 > 0 then zaddlt(queue, total+cost, i) end
end
end
cur, total = zshift(queue)
end
return nil
where the getcost function get a cost of edge from from to to nodes which is set by add_edge.lua script explained on the previous post.
-- dijkstra.lua:14
local function getcost(key, nnode, from, to)
return redis.call('HGET', key, nnode*from + to)
end
Result
Here, some example problems are solved by above code.
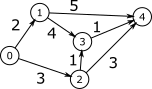
First is to find the minimum cost from node 0 to node 4 on above graph. You could find that the minimum cost becomes 5. My script also answers correctly:
% redis-cli EVAL "$(cat add_edge.lua)" 1 graph \
5 0 1 2 0 2 3 1 3 4 1 4 5 2 3 1 2 4 3 3 4 1
(nil)
% redis-cli EVAL "$(cat dijkstra.lua)" 2 graph queue 5 0 4
"5"
Good! But it can happen by chance since the graph is quite simple. So, I tested it by solving a Project Euler’s problem. Although I would not describe how to convert the problem to a shortest path problem, a resulting graph has 6,400 nodes and my script can calculate the correct answer to this problem, too.
However, my script is quite slow and takes about 19 seconds to solve the problem. On the other hand, my C++ implementation finishes instantly. I have not yet investigated the bottleneck of my code but I suspect that the loops in Lua are slow. Besides, my script has another bad point that is monolithic and occupies the Redis execution thread. It would be better to implement main algorithm part at client side for performance and granularity of execution. Anyway, it has been fun to pack a whole algorithm into Redis.
comments powered by Disqus